sony/flutter-elinux を使ってみた。
動機
以前、以下のような記事を書いてましたが、あれから2年。より簡単に使えるようになってるみたいだったので再度触ってみました。
sony/flutter-embedded-linux を使ってみる - bamchoh’s diary
sony/flutter-embedded-linux を使ってみた Raspberry Pi 4 (arm64) 編 - bamchoh’s diary
環境
Windows 11 (64bit) に Virtual Box 7.0 をインストールして 仮想環境に Debian 12 を使って weston が使える最小構成をインストールしています。
※ weston の最小構成は昨日の記事を参照してください。
Virtual Box を使って最小構成の Debian と Wayland / Weston をインストールするときの問題点 - bamchoh’s diary
sony/flutter-elinux
GitHub - sony/flutter-elinux: Flutter tools for embedded Linux (eLinux)
SONYの中の方が作成されている flutter を embed linux 環境で簡単に使えるようにしてくださっているようです。
リポジトリの README.md に記載の Quick Start をするだけで簡単に flutter が linux で起動できるので便利。
以下のように flutter-elinux をインストール
$ git clone https://github.com/sony/flutter-elinux.git $ sudo mv flutter-elinux /opt/ $ export PATH=$PATH:/opt/flutter-elinux/bin
次に flutter-elinux で使うツール群をインストール
$ sudo apt install unzip curl clang cmake pkg-config
Weston をインストールして起動
$ sudo apt install weston $ weston &
weston-desktop上でターミナルを起動してデバイスを作成(?)
$ flutter-elinux devices
Flutter のサンプルを実行
$ flutter-elinux create sample $ cd sample $ flutter-elinux run -d elinux-wayland
するとこんな感じで画面が表示されるかと思います。
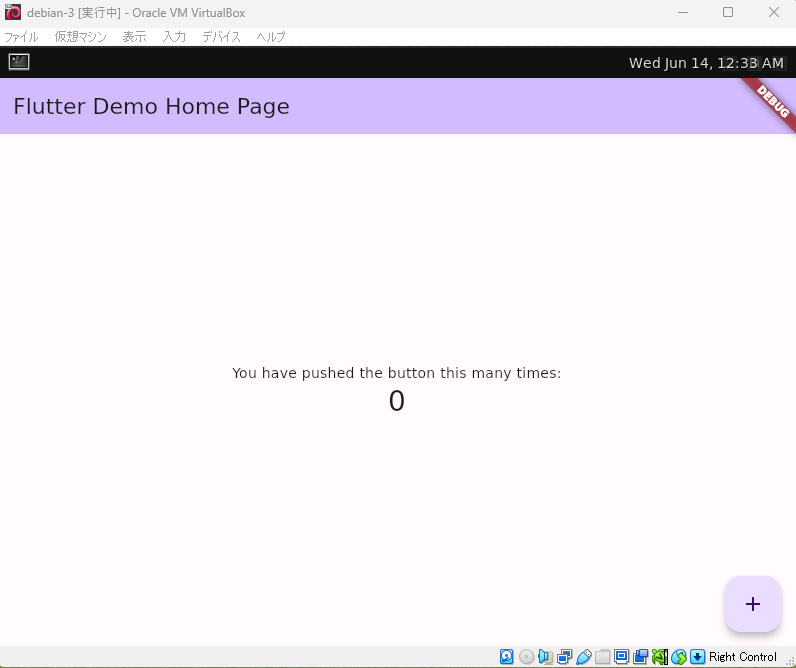
KIOSKモード (フルスクリーンモード) で表示
weston には KIOSKモードというものがあるらしいのですが、それだとうまく動かなかったのでデフォルトのshellを使ってflutterのサンプルアプリを起動します。そのための weston.ini が以下のものです。
[core] use-pixman=true idle-time=0 [keyboard] keymap_layout=jp [shell] client=/home/bamchoh/run.sh locking=false animation=fade allow-zap=true
色々設定していますが、重要なのは client の行で、ここに直接 sample コマンドを記述すると、なぜかコマンドライン引数がコマンドの一部と認識されてしまい起動できなかったので、シェルスクリプトを間に噛ましています。
シェルスクリプトは以下のように sample コマンドを実行するだけのシンプルなものです。
#!/usr/bin/bash /home/bamchoh/sample/build/elinux/x64/release/bundle/sample --bundle=/home/bamchoh/sample/build/elinux/x64/release/bundle
一応これで起動はするのですが、なぜか初回描画位置がおかしく頭に巨大なスペースが開いた状態で描画されてしまいます。この問題はまだ解決していないのですがマウスを動かすと治ります。謎です。
まとめ
Virtual Box 上の Debian 12 に対して sony/flutter-elinux をインストールして weston 上で キオスク表示してみました。 以前やった工程よりだいぶ楽に表示できた気がします。
Flutterは何もわからないですが、Raspberry Piとかと組み合わせると何か面白いことができそうな予感がします。
Virtual Box を使って最小構成の Debian と Wayland / Weston をインストールするときの問題点
Debian / Ubuntu上のwaylandとwestonで最小限のGUIを構築する - Qiita
Virtual Box でここ↑↑の通りに色々設定しようとして、いろいろ躓いたのでメモ。
仮想マシンの作成
いつからかわからないけど、Virtual Box で Debian の ISO イメージをインストールしようとすると、起動する前に GUIでユーザーとか入力できて、起動した瞬間からインストールが自動で始まって、起動終わるころにはインストールが終わってて「エキスパートインストール」ができないという問題があった。
「仮想マシンの作成」ダイアログの「Skip Unattended Installation」にチェックを入れるとこの現象は出なくなる。
エキスパートインストール
Virtual Box の仮想マシンの作成のところで「エキスパートモード」というものがあり、それが「エキスパートインストール」なのだと勘違いして何度も通常インストール(GUI)を使って GNONE無しのインストールをしてしまい、インストールあとに黒い画面が起動するだけで何もできないという問題に直面していた。
「エキスパートインストール」は Debian のインストーラーが起動して最初に出てくる選択画面の「Advanced options」の中にある「Expert install」のことなので注意すること
日本語でインストールすると、コンソールで文字化けする
これはあるあるだけど、日本語ロケールでインストールすると、インストールあとのコンソールで文字化けするのでいったん英語ロケールにしたほうがいいかも。
export LANG=en_US
libnss-resolve をインストールすると通信できなくなる
Naoyuki's PC Blog: systemd-resolveの設定(Ubuntuなどの動的DNS設定)
/etc/nsswitch.confのhosts行を理解する - えんでぃの技術ブログ
WSLにてapt update時の『Temporary failure resolving ~』を解決する方法 - Qiita
色々調べた結果、/etc/resolve.conf が書き換わってしまって DSNの名前解決ができない状態になっていたみたい。
systemd-resolved の設定ファイル /etc/systemd/resolved.conf を修正することで解決した
DNS=192.168.xxx.xxx
書き換えた後、 systemd-resolved を再起動
sudo systemctl restart systemd-resolved.service
これでOK
weston の起動
Running Weston — weston 12.0.90 documentation
logind: failed to get session seat (#616) · Issues · wayland / weston · GitLab
weston.ini(5) — Arch manual pages
westonを起動するときに config オプションを付けて起動する場合、フルパスを指定しないとちゃんと動作しないかも。
$ weston --config=/home/user1/weston.ini
あと、 weston.ini の中に xwayland=true を記述するとうまく動かないかもなので、指定しないほうがいいかも。
アプリケーションが終了するときに、子プロセスも終了させる方法
とある実行プロセス内で実行した別プロセスを親プロセスが死んだ段階で子プロセスも終了させたいというユースケースは結構あるかと思います。
Linuxではプロセスグループというものがあって、そのグループに属しているプロセスは親プロセスが死んだら子プロセスも一緒に終了してくれます。
Windowsにはプロセスグループに相当するものとしてジョブオブジェクトというものがあります。
同じジョブに属しているプロセスは親プロセスが死んだら一緒に子プロセスも死んでくれますが、プログラムでジョブにプロセスを登録してあげる必要があります。
C#での登録の仕方は以下のサイトに記述があります。今回はこれをGoで書いてみようと思います。
Goで書いてみると以下のような感じになりました。以下のコードの例では notepad を3つ立ち上げて 3秒後に終了するという単純なプログラムになっています。
大まかな流れとしては以下のような感じです。
CreateJobObjectでジョブを作成JOBOBJECT_BASIC_LIMIT_INFORMATION構造体のLimitFlagsにJOB_OBJECT_LIMIT_KILL_ON_JOB_CLOSEを設定したJOBOBJECT_EXTENDED_LIMIT_INFORMATION構造体を作成SetInformationJobObjectを作成した ジョブとJOBOBJECT_EXTENDED_LIMIT_INFORMATION構造体で実行AssignProcessToJobObjectに 子プロセスのプロセスを渡して登録する
package main import ( "os" "os/exec" "time" "unsafe" "golang.org/x/sys/windows" ) type JobObject struct { Handle windows.Handle } func CreateAsKillOnJobClose() (*JobObject, error) { job, err := windows.CreateJobObject(nil, nil) if err != nil { return nil, err } info := windows.JOBOBJECT_EXTENDED_LIMIT_INFORMATION{ BasicLimitInformation: windows.JOBOBJECT_BASIC_LIMIT_INFORMATION{ LimitFlags: windows.JOB_OBJECT_LIMIT_KILL_ON_JOB_CLOSE, }, } _, err = windows.SetInformationJobObject( job, windows.JobObjectExtendedLimitInformation, uintptr(unsafe.Pointer(&info)), uint32(unsafe.Sizeof(info))) if err != nil { panic(err) } return &JobObject{job}, nil } func (obj *JobObject) CloseHandle() error { return windows.CloseHandle(obj.Handle) } func (obj *JobObject) AssignProcess(p *os.Process) error { type process struct { Pid int Handle uintptr } if err := windows.AssignProcessToJobObject( obj.Handle, windows.Handle((*process)(unsafe.Pointer(p)).Handle)); err != nil { return err } return nil } func main() { cmds := make([]*exec.Cmd, 0) for i := 0; i < 3; i++ { cmd := exec.Command("notepad.exe") if err := cmd.Start(); err != nil { panic(err) } cmds = append(cmds, cmd) } jobObj, err := CreateAsKillOnJobClose() if err != nil { panic(err) } defer jobObj.CloseHandle() for _, cmd := range cmds { jobObj.AssignProcess(cmd.Process) } time.Sleep(3 * time.Second) }
懸念
上記の記事にも書かれているように親プロセスが終了すると子プロセスは強制終了させられるとのことで、ちゃんと終了したい場合は WM_CLOSE メッセージを送らないといけないかもとのことでした。
私のコード例ではそのあたりの処理が抜けているので、ちゃんとする場合はメッセージを送るような処理を入れる必要があるんでしょうね・・・
【読書感想ブログ】読書は一冊のノートにまとめなさい[完全版] - 奥野宜之 / ダイアモンド社
この題名を見たとき「書籍1冊につき、ノート1冊分の読書メモをとりなさい」という意味なのかな?と思っていましたが、読んでみると全然違って「本を探すところから、読書メモから全部を一冊のノートのまとめるとよりよい読書ライフができるよ!」という本でした。
去年の5月ごろから始めた読書感想ブログですけど、ブログを書いてもなんだか薄っぺらい感想しか書けなくてどうしたもんかなと思っていて、読書メモを取りながら読んだほうがいいんだろうなぁ~という漠然とした気持ちがあり、去年の後半くらいから読書メモを取るようにしてたんですが、メモのつもりがほぼほぼ写経みたいなことになってしまい、読書するのがただただ辛い修行のようなものになっていました。
この本の中でもそのようなことが書いていて、読書メモはできるだけとらないようにして、「通読」→「再読」→「マーキング」を経てから読書メモをとるようにしましょうと書いてありました。
「通読」はそのままの意味で、本を通読します。ただ、途中で気になったポイントや心に留まったところのページの上端を折っておきます。
「再読」は折ったページを読み返します。その時に、やっぱりここは重要だなと思うところのページの下端を折ります。
ここで「ページの両面にそういうポイントがあった場合はどうしたらいいの?」という疑問があると思いますが、それはどっちかを諦めるという割り切りが必要です。作者はこれも運命と受け入れて先に読み進むことを選ぶのだそう。私はあきらめきれないので、通読の時は右ページであれば上端、左ページであれば下端を折り曲げて、再読のときは折り曲げたページの端を再度折り曲げる方法でやっていこうかなと思っています。皆さんも独自のやり方を編み出してもいいかもしれませんね。
「再読」が終われば次は「マーキング」です。上下端が折られているページを再々読して「ここはやっぱり重要だな!」と思うポイントにマーカーを引きます。
「マーキング」が終わったらいよいよ読書メモを取ります。マーキングした文章を「写経」してノートに写して、その文章に対してコメントを続けて書きます。
これを繰り返すだけです。
私はこの方法プラス、読書メモのはじめにこの本はどういった本かの要約を書くようにしようかなと思っています。そうすることで、この本を人に話すときに説明しやすくなるんじゃないか?とか、読み返すときに「あぁ、こういう本だったな」ということがわかりやすくなるかなと思ったので。
作者は読書メモ以外にも「探書リスト」も読書メモと同じノートに残しておくようにすると良いと書かれています。そうすることで書籍を探す手間を省き、最短で良書に出会うことが可能になり最効率で読書が血肉となるのだということでした。
私はまだその境地まで至っていないので、今は気になった本のタイトルを付箋に書き出して張る。くらいにとどめておこうと思いました。
まとめ
この本を読んで、読書メモの取り方を変えてみました。お試しでこの本に対してこの本に書かれているやり方で読書メモを取ってみましたが、今までやっていた読書メモの取り方と比べて断然やりやすかったです。
しかも、メモの量が格段に少なくなって、濃縮された情報がノートに残されている感じがします。
また、自分のコメントを書くことで読み返したときに「そうそう!そう思ってた!」と読み返すのがちょっと楽しくなることを発見できて、「これはいいぞ」という手ごたえのようなものを感じています。
そのおかげか、このブログもスラスラかけた気がします(内容は稚拙かもですが)
なので、しばらくはこの方法でやってみようかなと思います。
そういうことで、この本は結構お勧めです。
rb_enc_prev_char の動き
このブログを見て、rb_enc_prev_char の動きが気になった。
まず、 String#rindex がほんとに HAVE_MEMRCHR がないからかどうかを検証。
$ git clone https://github.com/ruby/ruby
$ cd ruby
$ autoconf
$ ./configure
$ make
$ ruby -e 'p "\x00\x01\x80\x00".rindex("\x01")'
linux では 1 になる。しかし、string.c の str_rindex() の内容を無理やり HAVE_MEMRCHR の false 側にして再実行すると 2 になる。ということは、false側の str_rindex() に問題があることがわかる。
rb_enc_prev_char の実装はここにある。 ruby/encoding.h at v3_1_3 · ruby/ruby · GitHub
rb_enc_prev_char の中では onigenc_get_prev_char_head を呼んでいるだけっぽいので onigenc_get_prev_char_head の実装を見てみる。実装はこちら ruby/regenc.c at v3_1_3 · ruby/ruby · GitHub
onigenc_get_prev_char_head の中では ONIGENC_LEFT_ADJUST_CHAR_HEAD を呼んでるだけっぽいので ONIGENC_LEFT_ADJUST_CHAR_HEAD の実装を見てみる。実装はこちら ruby/onigmo.h at v3_1_3 · ruby/ruby · GitHub
ONIGENC_LEFT_ADJUST_CHAR_HEAD の中では各エンコーディングの left_adjust_char_head が呼ばれているだけっぽい ruby のデフォルトエンコーディングは UTF8なので、実装はUTF8のエンコーディングのソースにある。 ruby/utf_8.c at v3_1_3 · ruby/ruby · GitHub
left_adjust_char_head では utf8_islead()じゃなかったらポインタのマイナスを繰り返す。
utf8_islead() の実装はこちら ruby/utf_8.c at v3_1_3 · ruby/ruby · GitHub
#define utf8_islead(c) ((UChar )((c) & 0xc0) != 0x80)
文字を 0xc0 でマスクして 0x80 じゃなかったら true
ということは、0x80 ~ 0xBF なら ポインタがマイナスする。
str_rindex は pos を返すが、pos自体は1つずつしか減らないのに対して、rb_enc_prev_char は エンコーディングによって 2バイト以上減る可能性があることから問題が発生している。
ちなみに、Ruby3.2 ではこの点が解決されていて、 pos を返すのではなくて、 検索している文字列のポインタの位置から文字列の最初のポインタの位置を引いた値を返すようになっているので、ちゃんと 1 が返るようになっている。
ちなみに、 ruby 3.2 であっても、以下のようなコードは動作しない。
ruby -e 'p "\x00\x01\x80\x00".rindex("\x80")'
これは、検索文字列の \x80 が rb_env_prev_char でスキップされてしまうので検索文字列としてヒットしないため。
こういう場合はちゃんとエンコーディングを合わせるようにしないといけない。
ruby -e 'p "\x00\x01\x80\x00".b.rindex("\x80".b)'
まとめ
Ruby の文字列をバイト文字列として扱うには、そのままではダメ。ちゃんと String#b を使おう。
【読書感想ブログ】ドメイン駆動設計(モデリング/実装ガイド)
参考図書
設計なんもわからん
みなさん開発してますか?開発してるとぶち当たるカベがありますよね?
そうです設計です。
「このシステムどうやったら奇麗に作れるんだろう?」と日々思い悩みながら
あーでもないこーでもないと手探りで開発を進める日々ですよね?
一昔前であれば「デザインパターン」を覚えたり、GitHubの人気リポジトリのコードを
真似したりするのが主流でしたが、最近はドメイン駆動設計(通称:DDD)なるものが
巷で噂になってますよね?
私がDDDという単語を耳にするようになってからもう数年たちます。
なにやら難しそうだな~という感想を持ち幾星霜。いよいよ重い腰を上げて勉強してみようと思った次第です。
ドメイン駆動設計とは?
ドメイン駆動設計を説明するためにまずは「ドメイン」について説明しなければならないでしょう。
ドメインと聞くと、hatena.ne.jp のようなものを想像しますがこれではありません。
ドメインとは、「ソフトウェアが解決しようとしている問題の対象領域」のことを指す言葉です。
ドメイン自体は英語で「領域」とか「分野」なんて訳され方をするので単純に「問題の対象領域」と思っておけばいいかと思います。
そして、ドメイン駆動設計とは
ドメインに対してモデリングによってソフトウェアの価値を高めることを目指す開発手法 のことを指します。
モデル
「モデリングによってソフトウェアの価値を高める」ということですが、じゃぁ「モデリング」ってなんぞ?という話になりますよね?
「モデリング」はモデルを作成することです。「モデル」とは、問題解決のために物事の特定の側面を抽象化したもの になります。
ようは、家を作る前に設計図を引きますよね?その設計図のことをモデルという言葉で表現してると思ってもらえばいいと思います。
良いモデルとは?
「設計図ってことは外部仕様書や詳細設計仕様書ってことだろ?そんなのとうの昔からやっとりまんがな」という人もおられるかもしれません。
でもその仕様書、本当に役に立ってますか?
良いモデルとは 問題解決ができるモデルのこと をいいますが、その仕様書で問題解決できているならよい仕様書という事だと思います。
もし、そういう仕様書を作成できていない、もしくは今の仕様書に不満がある、もっというと仕様書なんて書いてなかった。。。という人にはこの本は役に立つ情報が乗っているかもしれません。
良いモデルを作るには
良いモデルを作るコツがあります。それは
- ドメインエキスパートと会話し、ドメインについての理解を深めモデルを作成
- そのモデルを元にソフトウェアを作成
- 運用してみて気づいた問題を再度ドメインエキスパートと会話しモデルを改善
- 改善したモデルを元にソフトウェアを作成
- 運用してみて問題に気づく→3に戻る
というサイクルを回すことです。
ドメインエキスパートとは、ドメイン(問題領域)に詳しい人のことです。
採用管理アプリなら人事担当者とかのことですね。
はじめは設計担当者にドメイン知識がなくともエキスパートに聞きながら作成することで
大きな間違いを犯すことなく開発が進められるというメリットがDDDにはあります。
なので、できるだけサイクルは小さく早く回すのがよいでしょう。
アジャイルとの親和性
この作成→改善のサイクルを回すという流れはアジャイルととても親和性が高いです。
というのもこのDDDの提唱者のエリックエヴァンスはアジャイルを意識してこの設計手法を考えているからですね。
なので、開発プロセスにアジャイルを取り入れるとDDDがやりやすくなるかもしれません。
ユビキタス言語
DDDの設計アプローチの一つに、「発見したモデルの言葉をすべての場所で使う」というものがあります。
例えば「商品」というモデルがあった時にそれを開発者だけではなくビジネス側の人間とも同じ言葉として使用するということです。
先ほどの「ドメイン」に複数の意味があってはならないということですね。
ある人はDDDの「ドメイン」を想像しているけど、ある人はURLの「ドメイン」を想像している。
その状態で会話をしてもいわゆる アンジャッシュのコント状態 になります。
なので、使用する言葉は関係するすべての場所で同じ認識をもって使うことが重要です。
それはコード内でも同様で、「商品」というモデルはコード中でも「商品」として扱います。
コード内に日本語が使えないのであれば、対応表を作成し、「商品」はコード上では「Goods」と表現することを明示してあげることが重要です。
そういう意味では英語圏の人たちは対応表を作成しなくてもいいのでDDDを取り入れやすいかもですね。
ユビキタス言語が必要な理由
DDDではモデルを何度も継続的にアップデートします。
そのアップデートの中でモデルとコードが乖離してしまうと変更に時間がかかってしまいます。
そしてバグも埋め込まれやすくなります。
そこで設計したモデルをそのままコードに落とし込めれば認識のずれがなくなり変更に強いソフトウェアとなります。
なので、極力モデルをそのままコードに落とし込むことを心がけましょう
DDDを実装するためのアーキテクチャ
DDDを実装するためのアーキテクチャは世の中に色々ありますが、
作者がオススメしているのは「オニオンアーキテクチャ」です。
DDDを行うための必要最小限のレイヤのみで構成されていながら
強力なアーキテクチャとなっています。
モデリング
作者はこの書籍の中でユースケース図とドメインモデル図を使ってモデリングを行っています。
これは作者の YouTube の中で紹介されている sudoモデリング の構成要素の一つです。
この書籍が出てから約2年後の YouTube で紹介されている sudoモデリング のほうが
より良いモデリング手法となっているのは明らかなので、そちらを参考にされたほうが
もしかするとよいかもしれません。約10分() の動画なので、サクッとみられてよいですよ (^^)
↓↓↓ 作者の YouTube 動画はコチラ ↓↓↓
さようなら軽量DDD。10分でわかるドメインモデリング - ドメイン駆動設計 - YouTube
DDD固有のモデリング手法
集約
集約とは「必ず守りたい強い整合性を持ったオブジェクトの集まり」のことです。
集約を設計・実装する時のルールとして以下の2点があります。
- 強い整合性の確保が必要なオブジェクト群を1つの集約にする
- トランザクションを必ず1つにする
集約オブジェクトを扱う時親となるオブジェクトを集約毎に1つ決めます。
その決められたオブジェクトを「集約ルート」と呼びます。
また、集約は必ず集約単位でリポジトリから取り出し、格納する時も集約単位で行います。
こうすることで整合性が保証します。
どの単位で集約を決めるかというのは機械的に決めることはできず
システム全体のバランスを考えて決めます。
集約は整合性を「強く」確保したいものを1つの集約とします。
整合性を求める全てのオブジェクトを1つにするわけではないので注意が必要です。
集約の境界の決め方はある程度経験と知識が必要になってくるので
一度決めてもおかしいと思ったらモデルを修正してより良い方向に改善し続けるサイクルを回すのが良いと思います。
また、トランザクションの範囲も考慮しながら集約の境界を決めるとよいでしょう。
集約を大きくしてしまってトランザクションのロックも不必要に広くとってしまうようなことになると
システム全体の性能劣化も起こってしまいます。適切なトランザクションの範囲となるように
集約のサイズを決定することが重要です。
境界付けられたコンテキスト
境界付けられたコンテキストとは「特定のモデルを定義・適用する境界を明示的に示したもの」です。
例えば「商品」というものをイメージする時、販売部と配送部ではイメージが異なります。
販売部では「商品」は販売するものであり、配送部では運ぶ対象です。
販売部で欲しい情報ややりたいことがそのまま配送部でも必要だとは限りません。
それぞれにやりたいこと、欲しい情報があったとして、それを一つのクラスで表現すると
複雑で混沌としたクラスになりがちです。
そうするよりも販売部用の商品クラスと配送部用の商品クラスを分けて実装したほうが
クラス自体の複雑さは抑えることができます。
設計の基本原則(高凝集・低結合)
コードを高凝集・低結合にした場合のメリットとして以下のようなものがあります。
- コードを読んで理解しやすくなる
- コードを修正・拡張しやすくなる
- 修正時にバグを埋め込みにくくなる
- 同じコードを別の場所で再利用しやすくなる
- テストを実施しやすくなる
昔、私が新入社員のころ、会社で言われていた「みんなが使える部品的なコード」を集めて
開発効率を上げようという取り組みを思い出しました。ようは「コードのモジュール化」を行いましょう。ということですね。
凝集度
凝集度とは「責務・データ・ふるまいの関連の強さ」の尺度です。
「このクラスは何をするクラスなのか?」という問いに対する答えがすべてのクラスで明確になっていれば高凝集であると言えるでしょう。
それをなすためには日ごろから責務について設計の段階で常に考えておく必要があります。
結合度
結合度とは「複数のクラス動詞が依存している度合い」の尺度です。
インターフェースや依存性の注入によって結合度を下げることができそうです。
オニオンアーキテクチャ
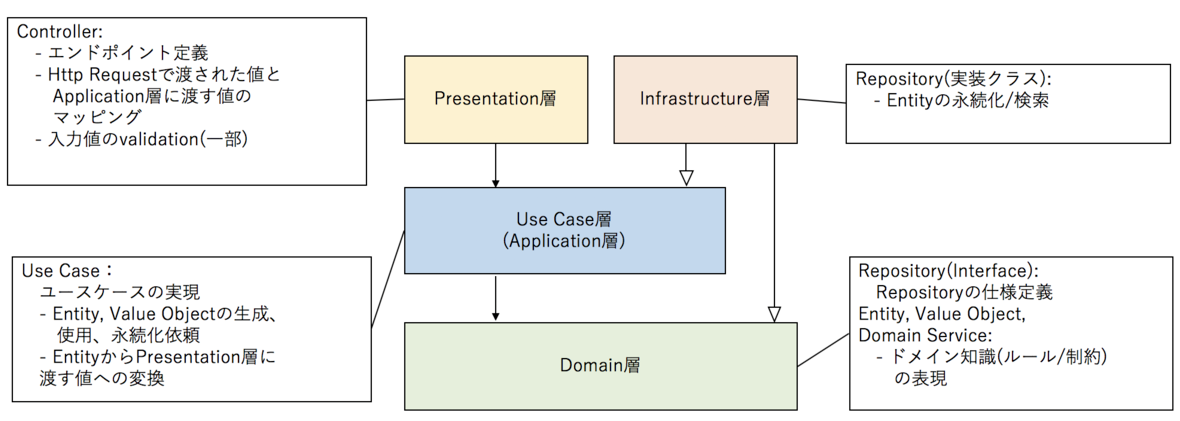
※ 図は 新卒にも伝わるドメイン駆動設計のアーキテクチャ説明(オニオンアーキテクチャ)[DDD] - little hands' lab より引用
オニオンアーキテクチャは
- プレゼンテーション層
- ユースケース層
- ドメイン層
- インフラストラクチャー層
の4層からなるアーキテクチャです。
レイヤードアーキテクチャの問題点をインフラ層とドメイン層の依存関係を逆にすることで解決しています。
プレゼンテーション層
ここはクライアントとの接点となり、エンドポイントの定義や Http Request で渡された値とユースケース層に渡す値とのマッピング、入力値の一部検証を行う責務があります。
ユースケース層
ユースケース層はドメインオブジェクトの生成・使用・永続化依頼を行います。
ドメインオブジェクトからプレゼンテーション層に渡す値の変換もこの層の責務です。
ユースケース層では「何をしたいか (What)」を書き、「どのように実装を実現するか(How)」はドメイン層に記述します。
ユースケースがそのまま記述できていることが理想です。
ドメイン層
ドメインモデルの知識を対応するオブジェクトに記述します。
常に正しいインスタンスしか存在させないことが重要です。
そうすることで、常に整合性が保証されます。
そのような実装にするには以下の2点を行います。
- 生成条件の強制(デフォルトのコンストラクタを使わずに、値が保証されるコンストラクタを定義したり、ファクトリメソッドを定義します)
- ミューテーション条件の強制(オブジェクトの整合性を保証して変更できるメソッドのみ公開します)
インフラ層
インフラ層はリポジトリを実装したり、ドメインオブジェクトの永続化・検索の実装が責務となります。
外部入出力とのコネクション
外部とのコネクションはプレゼン層やインフラ層にアダプタクラスを作成してアダプタクラスを経由してクライアントやデータベースとやり取りを行います。
テスト
DDDは繰り返しモデル・コードがアップデートされます。そのためテストコードは必須です。
ユースケースやドメインオブジェクト単位でテストを書き、CIを回すのが理想です。
境界付けられたコンテキストの実装
先ほど境界付けられたコンテキストは個々のグループでクラスを持つという話をしました。
個別にクラスを持つということはデータの同期が必要になるということです。
それを実現するために、グループ毎にアプリを作成しインフラ層のアダプタ間を接続して行う方法があります。
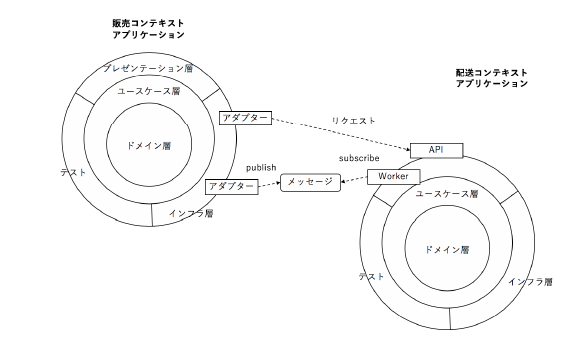
※ 図は『ドメイン駆動設計 モデリング 実装ガイド V1.0.3 P64』より引用
1アプリでやりたい場合は、パッケージで切り分けるという方法もあります。
ドメイン層の実装
ドメインモデルを表現するもの(ドメインオブジェクト)は以下の3つが存在しています
- エンティティ
- 値オブジェクト
- ドメインイベント (この本の範囲外)
ドメインオブジェクトを使用するものには主に以下のものがあります
値オブジェクト
値オブジェクトとは、世の中にある値をオブジェクトとして表現しているオブジェクトです。
たとえば「日付」だとか「金額」だとかがそれにあたります。
Date型やint型がすでにあるプログラミング言語であっても
業務内容によって制限があったりルールがあったりする場合は別途その用途に合った型を
値オブジェクトとして定義してあげることが重要です。
エンティティ
エンティティは値オブジェクトと似ていますが、同一性の判定は識別子で行われ、不変性も可変です。
値オブジェクトは同一性の判定を属性値で行い、普遍性は不変です。
ドメインサービス
ドメインサービスとは「モデルをオブジェクトとして表現すると無理があるもの」を表現するときに使用されます。
例えば、メールアドレスの重複チェックがそうです。複数のオブジェクトを操作してチェクする必要があるので
ドメインオブジェクト単体ではモデルを表現できません。
ただし、ドメインモデルは極力エンティティ・値オブジェクトとして表現するようにして
どうしても避けられない場合にのみドメインサービスを使うようにしましょう。
ドメインサービスはどうしても手続き型の実装になりがちで1サービスがファットなクラスになってしまいます。
リポジトリ
リポジトリとは「集約単位で永続化層へのアクセスを提供するもの」です。
リポジトリに渡すもの・返されるものは 必ず 集約ルートのエンティティになるように設計・実装します。
リポジトリを設計するときはリポジトリを List のように扱います。
List に具体的なメソッドが生えていないように
リポジトリにも抽象的なメソッドのみを生やし
ドメイン知識は別のクラスで実装するようにしましょう
ユースケース層
ドメイン層が整合性を保証できるメソッドのみを公開していれば
ユースケース層はそれを組み合わせて安心してユースケースを実現できます。
この組み合わせを行うことがユースケース層の責務になります。
ユースケースからの戻り値クラス
ユースケース層からプレゼンテーション層に返す値の型は
専用の戻り値クラスに詰め替えて返しましょう
ドメインオブジェクトをそのままプレゼンテーション層に渡してしまうと
往々にしてドメインオブジェクトにプレゼンテーション層のメソッドが生えてしまって
責務違反になってしまいます
CQRS
CQRSは Command Query Responsibility Segregation の略です。
CQRS は「参照に使用するクラスと更新に使用するクラスを分離する」というアーキテクチャです。
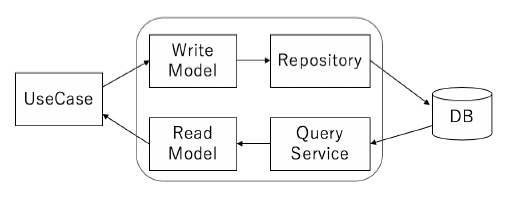
※ 図は『ドメイン駆動設計 モデリング 実装ガイド V1.0.3 P83』より引用
更新系のモデルはドメインオブジェクトをそのまま使用し
参照系のモデルは特定のユースケースに特化した値の型を定義し、
その値を取得する為のサービスも独自に定義します。
プレゼンテーション層
プレゼンテーション層はクライアントトアプリケーションの入出力を実現します。
HTMLテンプレートやルーティング設定もこのレイヤの責務です。
クライアントとの入出力に関するすべてのことはこのレイヤの責務と思っておけばいいでしょう。
WAFに依存する内容をこのレイヤに閉じ込めておければ
ユースケースレイヤ以外は依存なく実装が可能です
表示書式に関することもこのレイヤの責務で
"1,000円" という文字列を 1000 という数値に変換するのがこのレイヤです。
まとめ
DDDについて今までは新しい設計手法で、理解するのにすごく敷居が高いというイメージでしたが
この本を読んでDDDのエッセンスが知れた気がしました。
また、CQRSのような更新系と参照系を分離してクラス化する方法や
インフラ層とドメイン層の依存関係を逆転させるという方法が目からうろこで
この本を読んでよかったなと思えた点でした。
この本を軸にして別のDDD本も読んでDDDの理解を深めたいと思いました。
AWS IoT MQTT に Ruby で接続する
AWS IoT にモノを追加する
AWS IoT にアクセスして「モノ」を選択

「モノを作成」をクリック

「1つのモノを作成」を選択して「次へ」

任意のモノの名前を入力して「次へ」
※ ほかの項目はデフォルトでOK

「新しい証明書を自動生成(推奨)」を選択して「次へ」

「ポリシーを作成」をクリック

任意のポリシー名を入力して、以下のようにポリシーを設定して「作成」

「ポリシーをアタッチ」のページに戻って作成したポリシーを選択して「モノの作成」をクリック

証明書をダウンロードし「完了」をクリック
以下の3つをダウンロード
※ オプションで パブリックキーファイル、Amazon 信頼サービスエンドポイント CA3 も落としておくと良いかも?

「AWS IoT > 管理 > モノ」にモノが追加されていたらOK

エンドポイントの取得
AWS IoT の「設定」ページを表示する
※ 左のメニュー欄の下のほうにある。

「デバイスデータエンドポイント」に表示されている「エンドポイント」をコピーする

ruby-mqtt を使ってパブリッシャーを作る
ruby-mqtt をインストール
gem install mqtt
ruby スクリプト
require "mqtt" params = { host: "amkpd3vnlnx3d-ats.iot.us-west-2.amazonaws.com", port: 8883, ssl: true, cert_file: %q(<デバイス証明書>), key_file: %q(<プライベートキーファイル>), ca_file: %q(<Amazon 信頼サービスエンドポイント Amazon ルートCA1>), } MQTT::Client.connect(params) do |client| client.publish("test", "message") end
実行
MQTT テストクライアントページを表示
※ トピック test をサブスクライブする

ruby スクリプト実行
※ 各証明書は実行ディレクトリと同じ場所に配置しておくこと
ruby main.rb
結果がテストクライアントページに表示される

おまけ
無限に pub しながら sub するスクリプト
require "mqtt" params = { host: "*****", port: 8883, ssl: true, cert_file: "*****", key_file: "*****", ca_file: "*****", } t1 = Thread.new do MQTT::Client.connect(params) do |client| client.get("test") do |topic, message| puts "#{topic} : #{message}" end end end sleep(3) MQTT::Client.connect(params) do |client| loop do client.publish("test", "message") sleep(1) end end t1.join